消息队列杂谈
消息队列杂谈
本篇文章聊聊消息队列相关的东西,内容局限于我们为什么要用消息队列,消息队列究竟解决了什么问题,消息队列的选型。
为了更容易的理解消息队列,我们首先通过一个开发场景来切入。
不使用消息队列的场景
首先,我们假设A同学负责订单系统的开发,B、C同学负责开发积分系统、仓储系统。我们知道,在一般的购物电商平台上,我们下单完成后,积分系统会给下单的用户增加积分,然后仓储系统会按照下单时填写的信息,发出用户购买的商品。
那问题来了,积分系统、仓储系统如何感知到用户的下单操作?
你可能会说,当然是订单系统在创建完订单之后调用积分系统、仓储系统的接口了
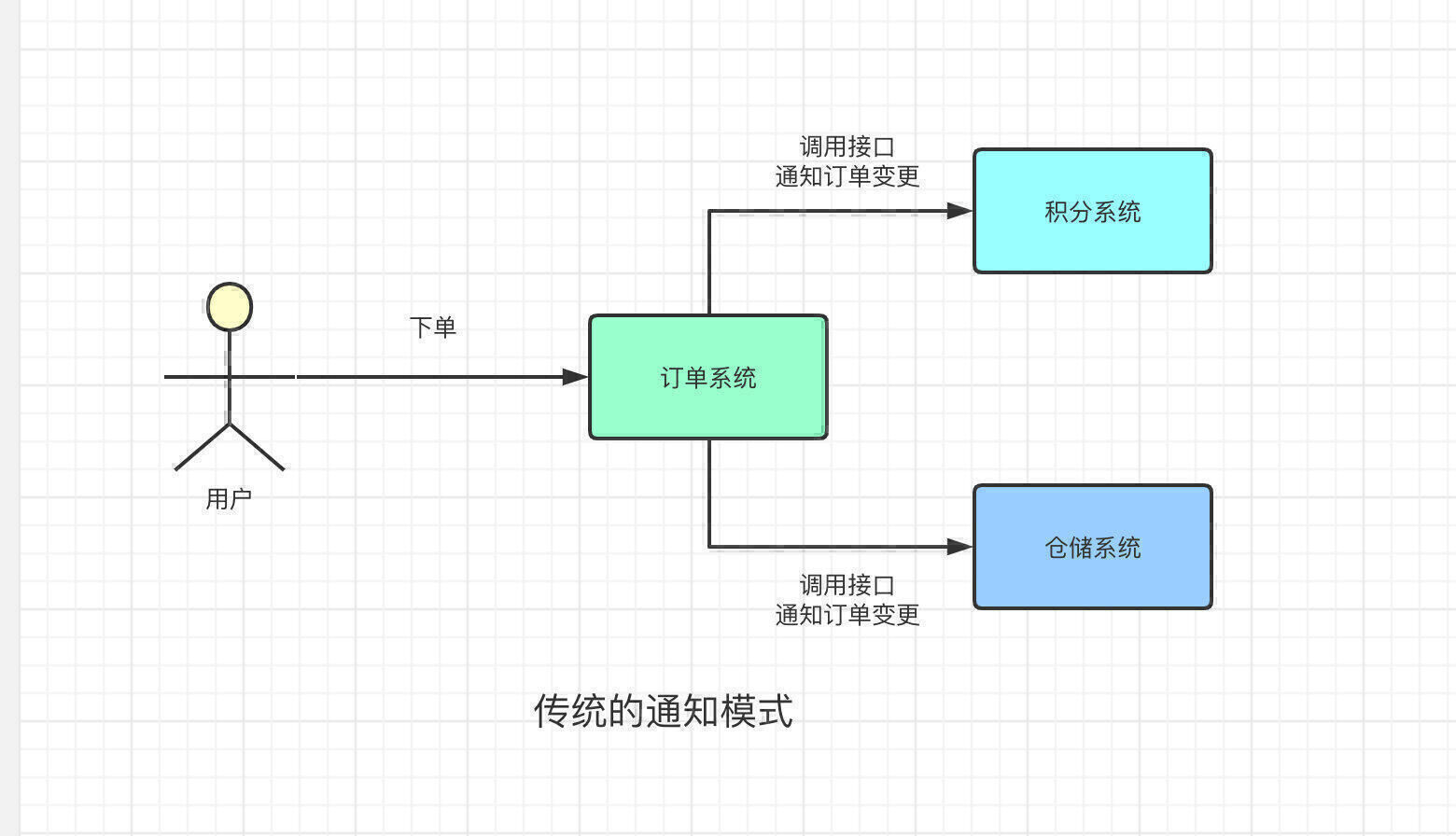
OK,直接调用接口的方式在目前来看没有什么问题。于是B、C同学就找到A同学,说让他在订单完成后,调用一下他们的接口来通知一下积分系统和仓储系统,来给用户增加积分、发货。A同学想着,就这两个系统,应该还好,OK我给你加了。
但是随着系统的迭代,需要感知订单操作的系统也越来越多,从之前的积分系统、仓储系统2个系统,扩充到了5个。每个系统的负责同学都需要去找A同学,让他人肉的把对应系统的通知接口加上。然后就因为加了这一个接口,又需要把订单重新发布一遍。
这对A同学来说实际上是很痛苦的一件事情,因为A同学有自己的任务、排期,一有新系统就需要去添加通知接口,发布服务,会打乱A的开发计划,增加开发量。同时还需要去梳理在开发期间,新增的代码到底能不能够上线。一旦不能上线,但是又没有检查到,上线就直接炸了。

而且,如果5个系统如果有哪个需要额外的字段,或者是更新了接口什么的,都需要麻烦A同学修改。5个系统就这样跟A系统强耦合在了一起。
除此之外,整个创建订单的调用链因为同步调用这5个系统的通知接口而加长,这减慢了接口的响应速度,降低了用户侧的购物、下单体验。前面的至少影响的还是内部的员工,但是现在直接是影响到了用户,明显是不可取的方案。
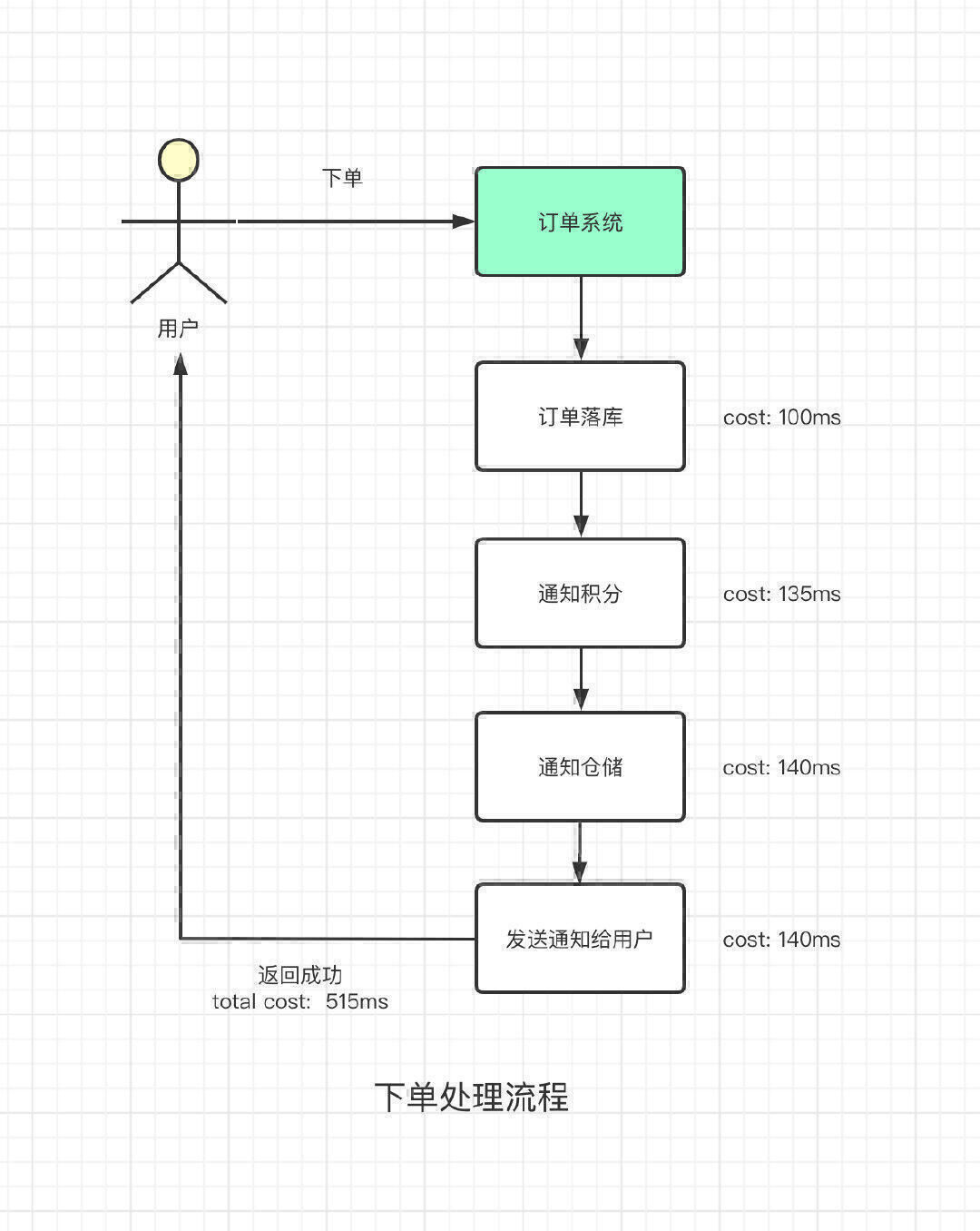
可以看到,整个的调用链路加长了,更别提,在同步调用中,如果其余的系统发生了错误,或者是调用其他系统的时候出现了网络抖动,核心的下单流程就会被阻塞住,甚至会在下单的界面提示提示用户出错,整个的购物体验又被拉低了一个档次。更何况,在实际的业务中,调用链比这个长的多。
可能有人会说了, 这不就是个同步调用问题嘛?订单系统的核心逻辑,我还是采用同步来处理,但是后续的通知我采用异步的方式,用线程池去处理,这样调用链路不就恢复正常了?
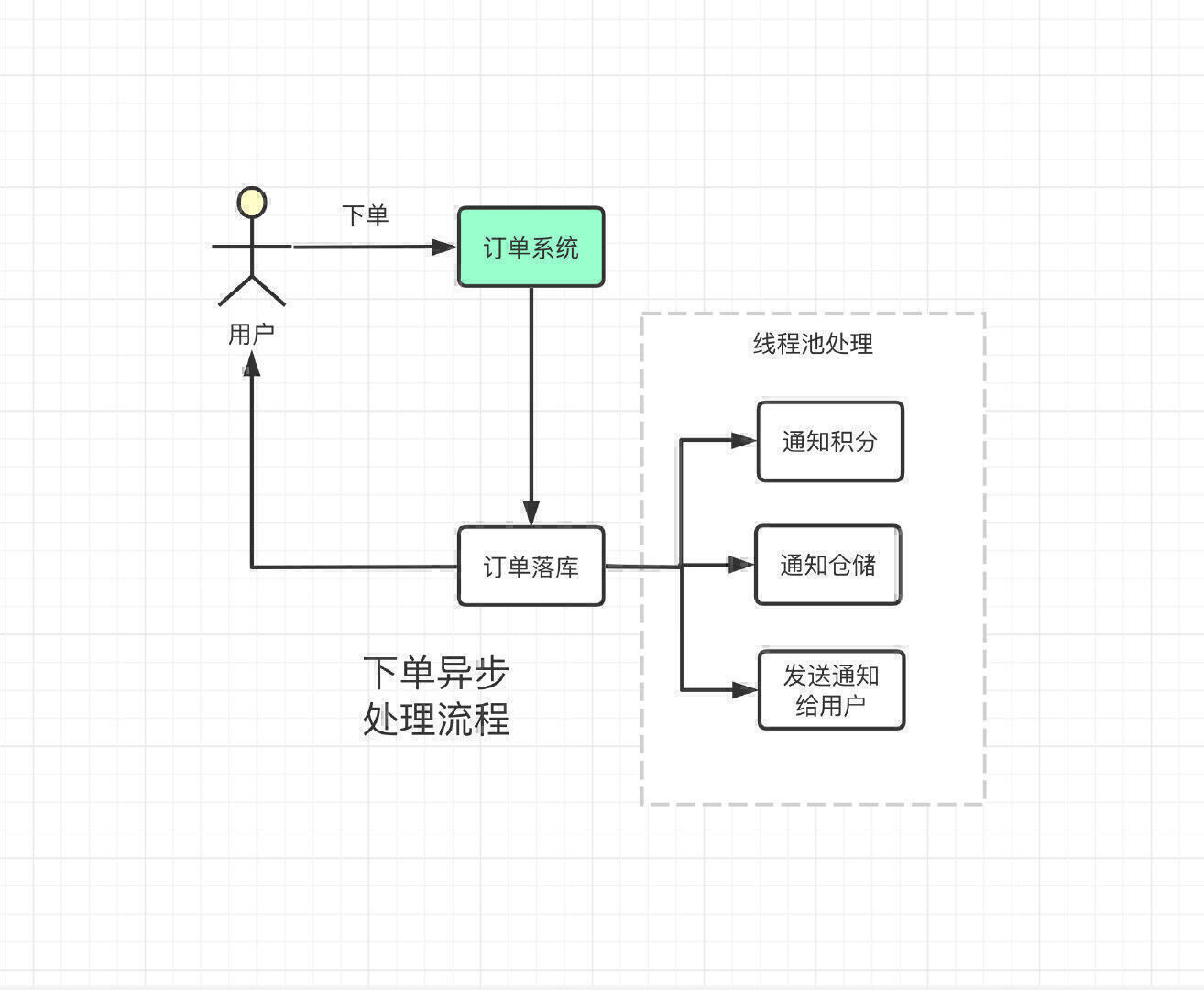
就单纯对于减少链路来说,的确可行。但是如果某一个流程失败了呢?难道失败就失败了吗?我下单成功了不涨积分?该给我发的货甚至没有发货?这合理吗?

同时,失败了订单系统是不是要去处理呢?否则因为其他的系统拉垮了整个主流程,谁还来你这买东西呢?
那有什么办法,既能够减少调用的链路,又能够在发生错误的时候重试呢?归根结底,核心思想就是像增加积分、返优惠券的流程不应该和主流程耦和在一起,更不应该影响主流程。
试想,我们能不能在订单系统完成自己的核心逻辑之后,把订单创建的消息放到一个队列中去,然后订单系统就返回给用户下单成功的结果了。然后其他的系统从这个队列中收到了下单成功的消息,就各自的去执行各自的操作,例如增加积分、返优惠券等等操作。
后续如果有新的系统需要感知订单创建的消息,直接去订阅这个队列,消费里面的消息就好了?这虽然跟真实的消息的队列有些出入,但其思路是完成吻合的。
为什么需要消息队列
通过上面的例子,我们大致就能够理解为什么要引入消息队列了,这里简单总结一下。
异步
对于实时性不是很高的业务,例如给用户发送短信、邮件通知,调用第三方的接口,都可以放到消息队列里去。因为相对于核心订单流程来说,短信、邮件晚一些发送,对用户来说影响不是很大。同时还可以提升整个链路的响应时间。
削峰
假设我们有服务A,是个无状态的服务。通过横向扩展,它可以轻松抗住1w的并发量,但是这N个服务实例,底层访问的都是同一个数据库。数据库能抗住的并发量是有限的,如果你的机器足够好的话,可能能够抗住5000的并发,如果服务A的所有请求全部打向数据库,会直接把数据打挂。

解耦
像上文举的例子,订单系统在创建了订单之后需要通知其他的所有系统,这样一来就把订单系统和其余的系统强耦合在了一起。后续的可维护性、扩展性都大大降低了。
而通过消息队列来关联所有系统,可以达到解耦的目的。

像上图这种模式,如果后续再有新系统需要感知订单创建的消息,只需要去消费「订单系统」发送到MQ中的消息即可。同样,订单系统如果需要感知其余系统的某些事件,也只是从MQ中消费即可。
通过MQ,达成服务之间的松耦合,服务内的高内聚,提升了服务的自治性。
消息队列选型
已知的消息队列有Kafka、RocketMQ、RabbitMQ和ActiveMQ。但是由于ActiveMQ现在用的公司比较少了,这里就不做讨论,我们着重讨论前三种。
Kafka
Kafka最初来自于LinkedIn,是用于做日志收集的工具,采用Java和Scala开发。其实那个时候已经有ActiveMQ了,但是在当时ActiveMQ没有办法满足LinkedIn的需求,于是Kafka就应运而生。
在2010年底,Kakfa的0.7.0被开源到了Github上。到了2011年,由于Kafka非常受关注,被纳入了Apache Incubator,所有想要成为Apache正式项目的外部项目,都必须要经过Incubator,翻译过来就是孵化器。旨在将一些项目孵化成完全成熟的Apache开源项目。
你也可以把它想象成一个学校,所有想要成为Apache正式开源项目的外部项目都必须要进入Incubator学习,并且拿到毕业证,才能走入社会。于是在2012年,Kafka成功从Apache Incubator毕业,正式成为Apache中的一员。
Kafka拥有很高的吞吐量,单机能够抗下十几w的并发,而且写入的性能也很高,能够达到毫秒级别。但是有优点就有缺点,能够达到这么高的并发的代价是,可能会出现消息的丢失。至于具体的丢失场景,我们后续会讨论。
所以一般Kafka都用于大数据的日志收集,这种日志丢个一两条无伤大雅。
而且Kafka的功能较为简单,就是简单的接收生产者的消息,消费者从Kafka消费消息。
RabbitMQ
RabbitMQ是很多公司对于ActiveMQ的替代方法,现在仍然有很多公司在使用。其优点在于能保证消息不丢失,同Kafka,天平往数据的可靠性方向倾斜必然导致其吞吐量下降。其吞吐量只能够达到几万,比起Kafka的十万吞吐来说,的确是较低的。如果遇到需要支撑特别高并发的情况,RabbitMQ可能会无法胜任。
但是RabbitMQ有比Kafka更多的高级特性,例如消息重试和死信队列,而且写入的延迟能够降低到微妙级,这也是RabbitMQ一大特点。
但RabbitMQ还有一个致命的弱点,其开发语言为Erlang,现在国内精通Erlang的人不多,社区也不怎么活跃。这也就导致可能公司内没有人能够去阅读Erlang的源码,更别说基于其源码进行二次开发或者排查问题了。所以就存在RabbitMQ出了问题可能公司里没人能够兜的住,维护成本非常的高。
之所以有中小型公司还在使用,是觉得其不会面临高并发的场景,RabbitMQ的功能已经完全够用了。
RocketMQ
RocketMQ来自阿里,同Kakfa一样也是从Apache Incubator出来的顶级项目,用Java语言进行开发,单机吞吐量和Kafka一样,也是十w量级。
RocketMQ的前身是阿里的MetaQ项目,2012年在淘宝内部大量的使用,在阿里内部迭代到3.0版本之后,将MetaQ的核心功能抽离出来,就有了RocketMQ。RocketMQ整合了Kafka和RabbitMQ的优点,例如较高的吞吐量和通过参数配置能够做到消息绝对不丢失。
其底层的设计参考了Kafka,具有低延迟、高性能、高可用的特点。不同于Kafka的单一日志收集功能,RocketMQ被广泛运用于订单、交易、计算、消息推送、binlog分发等场景。
之所以能够被运用到多种场景,这要归功于RocketMQ提供的丰富的功能。例如延迟消息、事务消息、消息回溯、死信队列等等。
- 延迟消息 就是不会立即消费的消息,例如某个活动开始前15分钟提醒用户这样的场景
- 事务消息 其主要解决数据库事务和MQ消息的数据一致性,例如用户下单,先发送消息到MQ,积分增加了,但是订单系统在发出消息之后挂了。这样用户并没有下单成功,但是积分却增加了,明显是不符合预期的
- 消息回溯 顾名思义,就是去消费某个Topic下某段时间的历史消息
- 死信队列 没有被正常消费的消息,首先会按照RocketMQ的重试机制重试,当达到了最大的重试次数之后,如果消费仍然失败,RocketMQ不会立即丢掉这条消息,而是会把消息放入死信队列中。放入死信队列的消息会在3天后过期,所以需要及时的处理
消息队列会丢消息吗
在不使用消息队列的场景中,我们吹了很多消息队列的优点,但同时也提到了消息队列可能会丢失消息,我们也可以通过参数的配置来使消息绝对不丢失。
那消息是在什么情况下丢失的呢?消息队列中的角色可以分为3类,分别是生产者、MQ和消费者。一条消息在整个的传输链路中需要经过如下的流程。
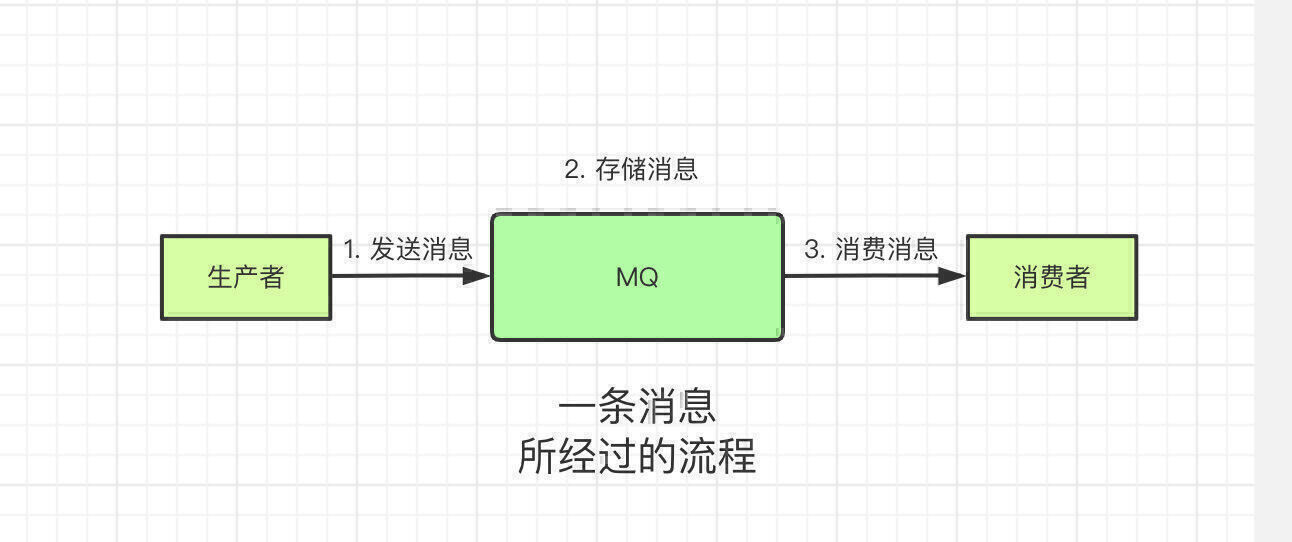
生产者将消息发送给MQ,MQ接收到这条消息后会将消息存储到磁盘上,消费者来消费的时候就会把消息返给消费者。先给出结论,在这3种场景下,消息都有可能会丢失。
接下来我们一步一步来分析一下。
生产者发送消息给MQ
生产者在发送消息的过程中,由于某些意外的情况例如网络抖动等,导致本次网络通信失败,消息并没有被发送给MQ。
MQ存储消息
当MQ接收到了来自生产者的消息之后,还没有来得及处理,MQ就突然宕机,此时该消息也会丢失。
即使MQ开始处理消息,并且将该消息写入了磁盘,消息仍然可能会丢失。因为现代的操作系统都会有自己的OS Cache,因为和磁盘交互是一件代价相当大的事情,所以当我们写入文件的时候会先将数据写入OS Cache中,然后由OS调度,根据策略触发真正的I/O操作,将数据刷入磁盘。
而在刷入磁盘之前,MQ如果宕机,在OS Cache中的数据就会全部丢失。
消费者消费消息
当消息顺利的经历了生产者、MQ之后,消费者拉取到了这条消息,但是当其还没来得及处理的时候,消费者突然宕机了,这条消息就丢了(当然你如果没有提交Offset的话,重启之后仍然可以消费到这条消息)
原来我们以为用上了消息队列,就万无一失了,没想到逐步分析下来能有这么多坑。任何一个步骤出错都有可能导致消息丢失。那既然这样,上文提到的可以通过参数配置来实现消息不会丢失是怎么一回事呢?
这里我们不去聊具体的MQ是如何实现的,我们来聊聊消息零丢失的实现思路。
消息最终一致性方案
涉及到的系统有订单系统、MQ和积分系统,订单系统为生产者,积分系统为消费者。
首先订单系统发送一个订单创建的消息给MQ,该消息的状态为Prepare状态,状态为Prepare状态的消息不会被消费者给消费到,所以可以放心的发送。
然后订单系统开始执行自身的核心逻辑,你可能会说,订单系统本身的逻辑执行失败了怎么办?刚刚的prepare消息不就成了脏数据?实际上在订单系统的事务失败之后,就会触发回滚操作,就会向MQ发送消息,将该条状态为Prepare的数据给删除。
订单系统核心事务成功之后,就会发送消息给MQ,将状态为prepare的消息更新为commit。没错,这就是2PC,一个保证分布式事务数据一致性的协议。
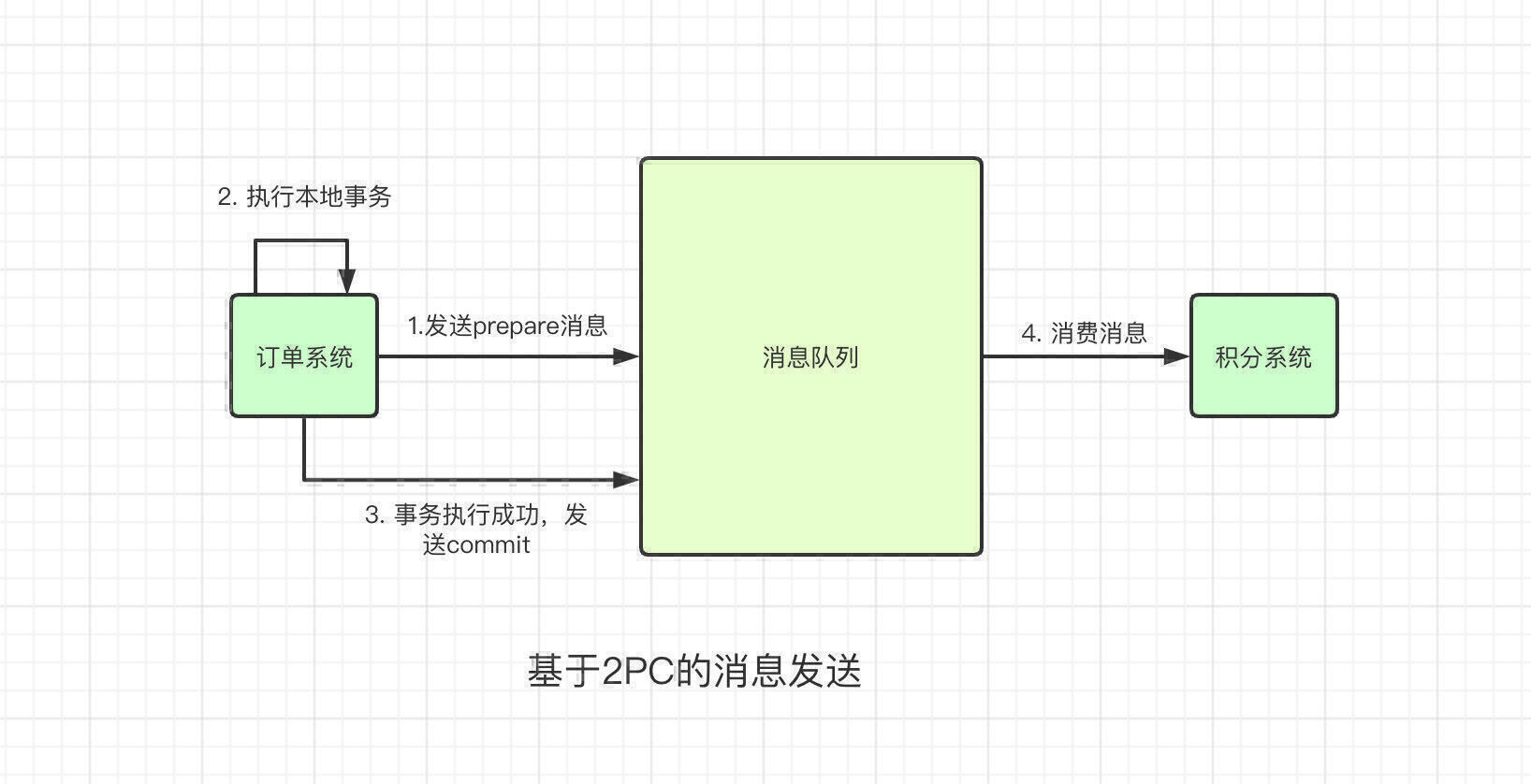
眼尖的你可能发现了一个问题,我发送了prepare消息之后,还没来得及执行本地事务,订单系统就挂了怎么办?此时订单系统即使重启也不会向MQ发送删除操作,这个prepare消息不就是一直存在MQ中了?
先给出结论,不会。
如果订单系统发送了prepare消息给MQ之后自己就宕机了,MQ确实会存在一条不会被commit的数据。MQ为了解决这个问题,会定时轮询所有prepare的消息,跟对应的系统沟通,这条prepare消息是要进行重试还是回滚。所以prepare消息不会一直存在于MQ中。这样一来,就保证了消息对于生产者的DB事务和MQ中消息的数据一致性。
再来看一种更加极端的情况,假设订单系统本地事务执行成功之后,发送了commit消息到MQ,此时MQ突然挂了。导致MQ没有收到该commit消息,在MQ中该消息仍然处于prepare状态,这怎么办?
同样的,依赖于MQ的轮询机制和订单系统沟通,订单系统会告诉MQ这个事务已经完成了,MQ就会将这条消息设置成commit,消费者就可以消费到该消息了。
接下来的流程就是消息被消费者消费了,如果消费者消费消息的时候本地事务失败了,则会进行重试,再次尝试消费这条消息。