基于Redo Log和Undo Log的MySQL崩溃恢复流程
基于Redo Log和Undo Log的MySQL崩溃恢复流程
在之前的文章「简单了解InnoDB底层原理」聊了一下MySQL的Buffer Pool。这里再简单提一嘴,Buffer Pool是MySQL内存结构中十分核心的一个组成,你可以先把它想象成一个黑盒子。
黑盒下的更新数据流程
当我们查询数据的时候,会先去Buffer Pool中查询。如果Buffer Pool中不存在,存储引擎会先将数据从磁盘加载到Buffer Pool中,然后将数据返回给客户端;同理,当我们更新某个数据的时候,如果这个数据不存在于Buffer Pool,同样会先数据加载进来,然后修改修改内存的数据。被修改过的数据会在之后统一刷入磁盘。
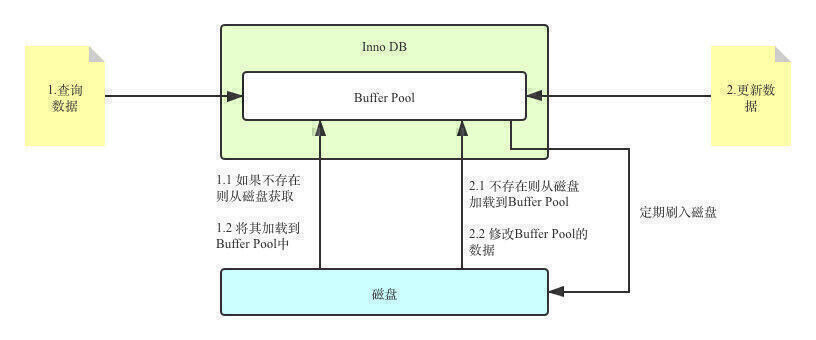
这个过程看似没啥问题,实则不讲武德。假设我们修改Buffer Pool中的数据成功,但是还没来得及将数据刷入磁盘MySQL就挂了怎么办?按照上图的逻辑,此时更新之后的数据只存在于Buffer Pool中,如果此时MySQL宕机了,这部分数据将会永久的丢失;
再者,我更新到一半突然发生错误了,想要回滚到更新之前的版本,该怎么办?那不完犊子吗,连数据持久化的保证、事务回滚都做不到还谈什么崩溃恢复?
Redo Log & Undo Log
而通过MySQL能够实现崩溃恢复的事实来看,MySQL必定实现了某些骚操作。没错,这就是接下来我们要介绍的另外的两个关键功能,Redo Log和Undo Log。
这两种日志是属于InnoDB存储引擎的日志,和MySQL Server的Binlog不是一个维度的日志。
- Redo Log 记录了此次事务**「完成后」的数据状态,记录的是更新之「后」**的值
- Undo Log 记录了此次事务**「开始前」的数据状态,记录的是更新之「前」**的值
所以这两种日志有明显的区别,我用一种更加通俗的例子来解释一下这两种日志。
Redo Log就像你在命令行敲了很长的命令,敲回车执行,结果报错了。此时我们只需要再敲个↑就会拿到上一条命令,再执行一遍即可。
Undo Log就像你刚刚在Git中Commit了一下,然后再做一个较为复杂的改动,但是改着改着你的心态崩了,不想要刚刚的改动了,于是直接git reset --hard $lastCommitId回到了上一个版本。
实现日志后的更新流程
有了Redo Log和Undo Log,我们再将上面的那张图给完善一下。
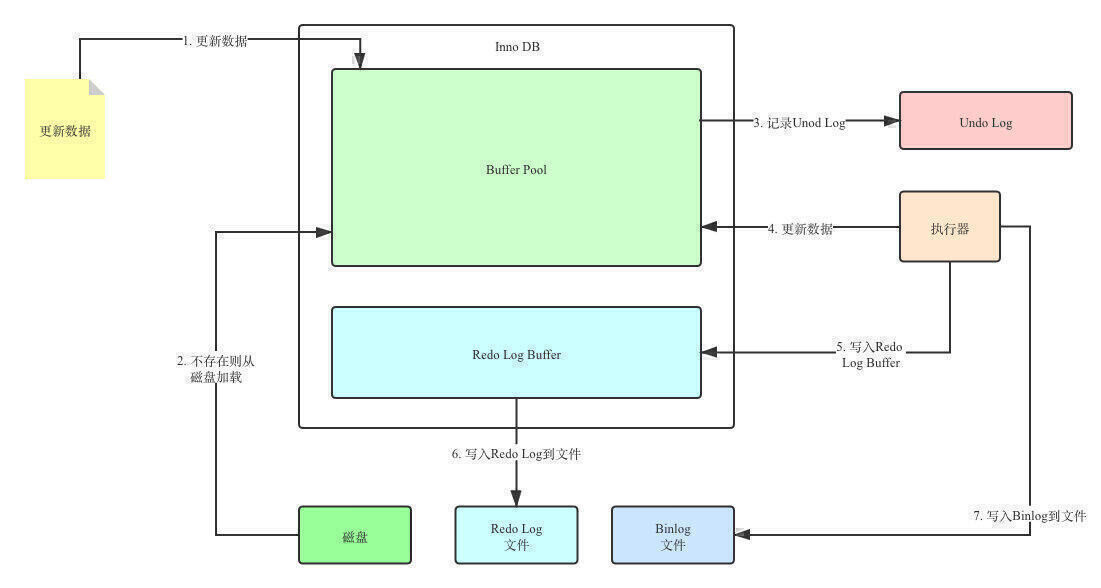
首先,更新数据还是会判断数据是否存在于Buffer Pool中,不存在则加载。上面我们提到了回滚的问题,在更新Buffer Pool中的数据之前,我们需要先将该数据事务开始之前的状态写入Undo Log中。假设更新到一半出错了,我们就可以通过Undo Log来回滚到事务开始前。
然后执行器会更新Buffer Pool中的数据,成功更新后会将数据最新状态写入Redo Log Buffer中。因为一个事务中可能涉及到多次读写操作,写入Buffer中分组写入,比起一条条的写入磁盘文件,效率会高很多。
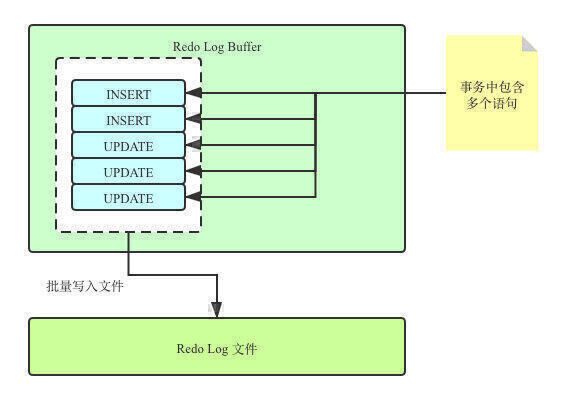
那为什么Undo Log不也搞一个Undo Log Buffer,也给Undo Log提提速,雨露均沾?那我们假设有这个一个Buffer存在于InnoDB,将事务开始前的数据状态写入了Undo Log Buffer中,然后开始更新数据。
突然啪一下,很快啊,MySQL由于意外进程退出了,此时会发生一件很尴尬的事情,如果更新的数据一部分已经刷回磁盘了,但是此时事务没有成功需要回滚,你发现Undo Log随着进程退出一起没了,此时就没有办法通过Undo Log去做回滚。
那如果刚刚更新完内存,MySQL就挂了呢?此时Redo Log Buffer甚至都可能没有写入,即使写入了也没有刷到磁盘,Redo Log也丢了。
其实无所谓,因为意外宕机,该事务没有成功,既然事务事务没有成功那就需要回滚,而MySQL重启后会读取磁盘上的Redo Log文件,将其状态给加载到Buffer Pool中。而通过磁盘Redo Log文件恢复的状态和宕机前事务开始前的状态是一样的,所以是没有影响的。然后等待事务commit了之后就会将Redo Log和Binlog刷到磁盘。
流程中仍然存在的问题
你可能认为到这一步就完美了,事实上则不然。假设我们在将Redo Log刷入到磁盘之后MySQL突然宕机了,binlog还没有来得及写入。此时重启,Redo Log所代表的状态就和Binlog所代表的状态不一致了。Redo Log恢复到Buffer Pool中的某行的A字段是3,但是任何监听其Binlog的数据库读取出来的数据确是2。
即使Redo Log和Binlog都写入文件了,但是这个时候MySQL所在的物理机活着VM宕机了,日志仍然会丢失。现在的OS在你写入文件的时候,会先将改动的内容写入的OS Cache中,以此来提高效率。然后根据策略(受你配置的参数的影响)来将OS Cache中的数据刷入磁盘。
基于2PC的一致性保障
从这你可以发现一个关键的问题,那就是必须保证Redo Log和Binlog在事务提交时的数据一致性,要么都存在,要么都不存在。MySQL是通过 **2PC(two-phase commit protocol)**来实现的。
简单介绍一下2PC,它是一种保证分布式事务数据一致性的协议,它中文名叫两阶段提交,它将分布式事务的提交拆分成了2个阶段,分别是Prepare和Commit/Rollback。
就向两个拳击手开始比赛之前,裁判会在中间确认两个选手的状态,类似于问你准备好了吗?得到确认之后,裁判才会说Fight。
裁判询问选手的状态,对应的是第一阶段Prepare;得到了肯定的回答之后,裁判宣布比赛正式开始,对应的是第二阶段Commit,但是如果有一方选手没有准备好,裁判会宣布比赛暂停,此时对应的是第一阶段失败的情况,第二阶段的状态会变为Rollback。裁判就对应2PC中的协调者Coordinator,选手就对应参与者Participant。
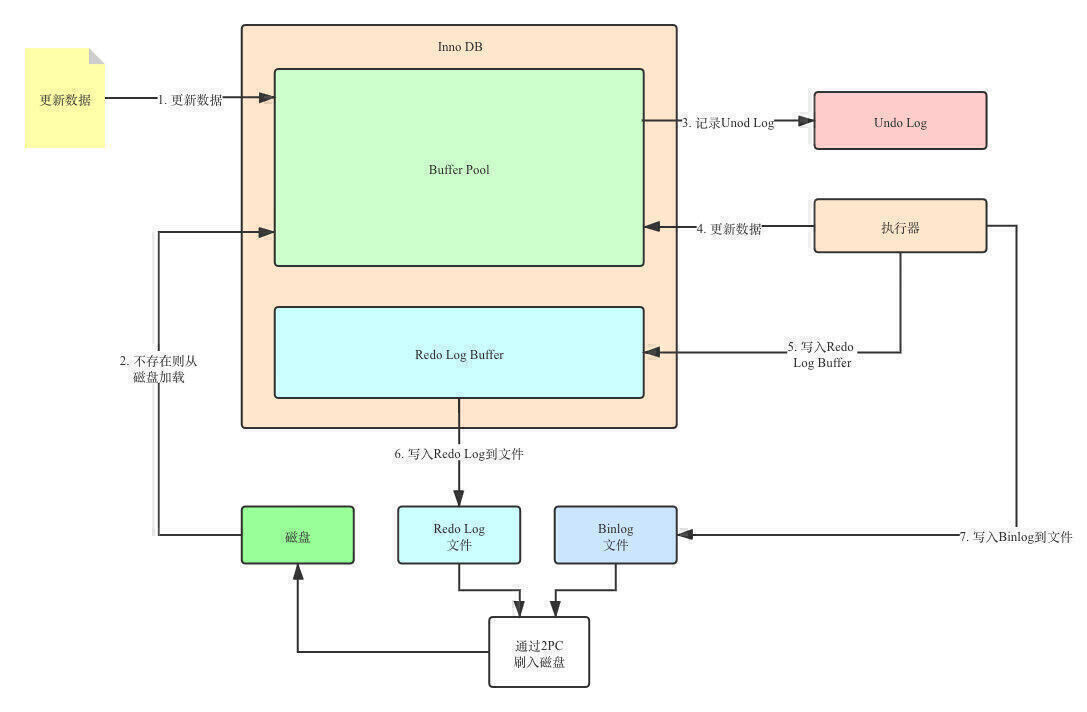
下面我们通过一张图来看一下整个流程。
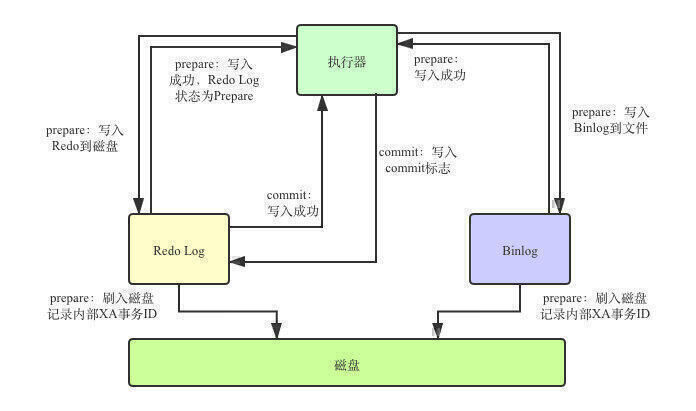
Prepare阶段,将Redo Log写入文件,并刷入磁盘,记录上内部XA事务的ID,同时将Redo Log状态设置为Prepare。Redo Log写入成功后,再将Binlog同样刷入磁盘,记录XA事务ID。
Commit阶段,向磁盘中的Redo Log写入Commit标识,表示事务提交。然后执行器调用存储引擎的接口提交事务。这就是整个过程。
验证2PC机制的可用性
这就是2PC提交Redo Log和Binlog的过程,那在这个期间发生了异常,2PC这套机制真的能保证数据一致性吗?
假设Redo Log刷入成功了,但是还没来得及刷入Binlog MySQL就挂了。此时重启之后会发现Redo Log并没有Commit标识,此时根据记录的XA事务找到这个事务,进行回滚。
如果Redo Log刷入成功,而且Binlog也刷入成功了,但是还没有来的及将Redo Log从Prepare改成Commit MySQL就挂了,此时重启会发现虽然Redo Log没有Commit标识,但是通过XID查询到的Binlog却已经成功刷入磁盘了。
此时,虽然Redo Log没有Commit标识,MySQL也要提交这个事务。因为Binlog一旦写入,就可能会被从库或者任何消费Binlog的消费者给消费。如果此时MySQL不提交事务,则可能造成数据不一致。而且目前Redo Log和Binlog从数据层面上,其实已经Ready了,只是差个标志位。