深入剖析 MySQL 自增锁
深入剖析 MySQL 自增锁
之前的文章把 InnoDB 中的所有的锁都介绍了一下,包括意向锁、记录锁...自增锁巴拉巴拉的。但是后面我自己回过头去看的时候发现,对自增锁的介绍居然才短短的一段。
其实自增锁(AUTO-INC Locks)这块还是有很多值得讨论的细节,例如在并发的场景下,InnoDB 是如何保证该值正确的进行自增的,本章就专门来简单讨论一下 InnoDB 中的自增锁。
什么是自增锁
之前我们提到过,自增锁是一种比较特殊的表级锁。并且在事务向包含了 AUTO_INCREMENT 列的表中新增数据时就会去持有自增锁,假设事务 A 正在做这个操作,如果另一个事务 B 尝试执行 INSERT语句,事务 B 会被阻塞住,直到事务 A 释放自增锁。
这怎么说呢,说他对,但是他也不完全对。
行为与限制
其实上面说的那种阻塞情况只是自增锁行为的其中一种,可以理解为自增锁就是一个接口,其具体的实现有多种。具体的配置项为 innodb_autoinc_lock_mode ,通过这个配置项我们可以改变自增锁中运行的一些细节。
并且,自增锁还有一个限制,那就是被设置为 AUTO_INCREMENT 的列必须是索引,或者该列是索引的一部分(联合索引),不过这个限制对于大部分开发场景下并没有什么影响。
毕竟我们的基操不就是把 id 设置为
AUTO_INCREMENT吗。
锁模式
其实在 InnoDB 中,把锁的行为叫做锁模式可能更加准确,那具体有哪些锁模式呢,如下:
- 传统模式(Traditional)
- 连续模式(Consecutive)
- 交叉模式(Interleaved)
分别对应配置项 innodb_autoinc_lock_mode 的值0、1、2.
看到这就已经知道为啥上面说不准确了,因为三种模式下,InnoDB 对并发的处理是不一样的,而且具体选择哪种锁模式跟你当前使用的 MySQL 版本还有关系。
在 MySQL 8.0 之前,InnoDB 锁模式默认为连续模式,值为1,而在 MySQL 8.0 之后,默认模式变成了交叉模式。至于为啥会改变默认模式,后面会讲。
传统模式
传统模式(Traditional),说白了就是还没有锁模式这个概念时,InnoDB 的自增锁运行的模式。只是后面版本更新,InnoDB 引入了锁模式的概念,然后 InnoDB 给了这种以前默认的模式一个名字,叫——传统模式。
传统模式具体是咋工作的?
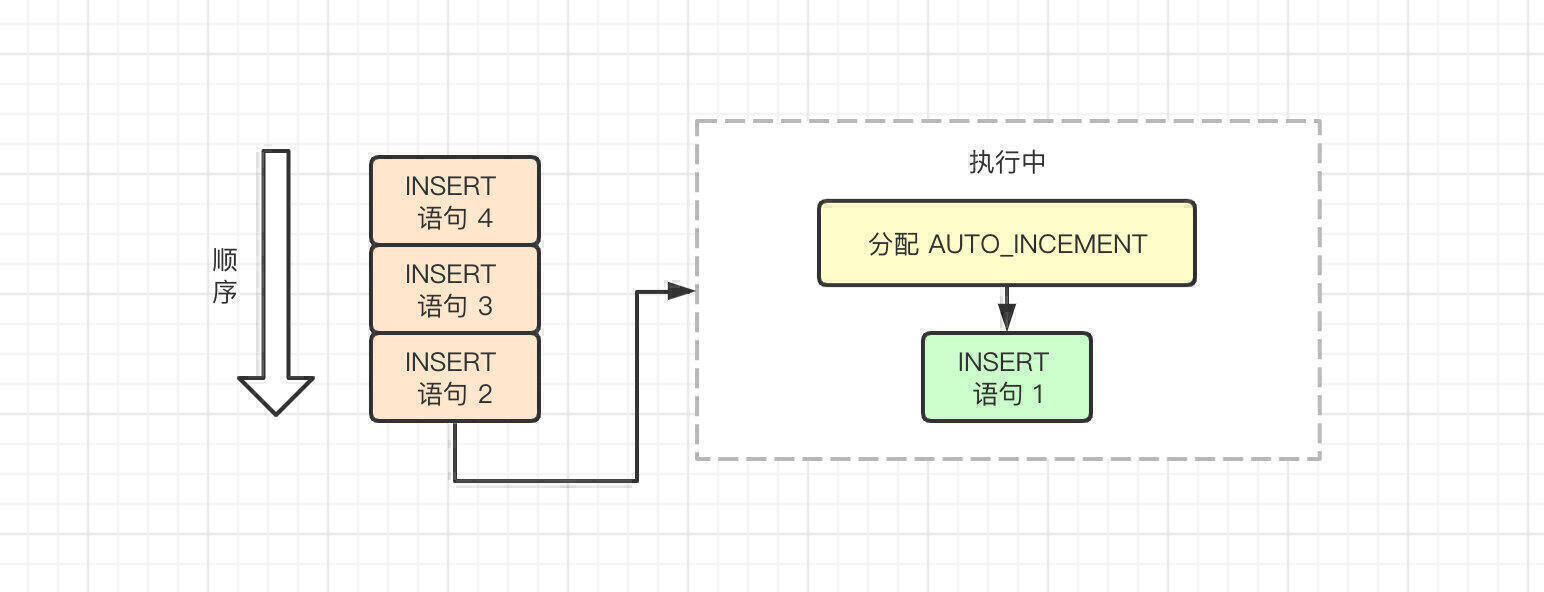
我们知道,当我们向包含了 AUTO_INCREMENT 列的表中插入数据时,都会持有这么一个特殊的表锁——自增锁(AUTO-INC),并且当语句执行完之后就会释放。这样一来可以保证单个语句内生成的自增值是连续的。
这样一来,传统模式的弊端就自然暴露出来了,如果有多个事务并发的执行 INSERT 操作,AUTO-INC的存在会使得 MySQL 的性能略有下降,因为同时只能执行一条 INSERT 语句。
连续模式
连续模式(Consecutive)是 MySQL 8.0 之前默认的模式,之所以提出这种模式,是因为传统模式存在影响性能的弊端,所以才有了连续模式。
在锁模式处于连续模式下时,如果 INSERT 语句能够提前确定插入的数据量,则可以不用获取自增锁,举个例子,像 INSERT INTO 这种简单的、能提前确认数量的新增语句,就不会使用自增锁,这个很好理解,在自增值上,我可以直接把这个 INSERT 语句所需要的空间留出来,就可以继续执行下一个语句了。
当然,这里其实并非什么锁也不用。在实际分配 ID 的过程中,InnoDB 会使用较为轻量级的 mutex 锁,来防止 ID 重复分配,ID 一旦分配好了,mutex 锁就会被释放。
但是如果 INSERT 语句不能提前确认数据量,则还是会去获取自增锁。例如像 INSERT INTO ... SELECT ... 这种语句,INSERT 的值来源于另一个 SELECT 语句。
连续模式的图和交叉模式差不多
交叉模式
交叉模式(Interleaved)下,所有的 INSERT 语句,包含 INSERT 和 INSERT INTO ... SELECT ,都不会使用 AUTO-INC 自增锁,而是使用较为轻量的 mutex 锁。这样一来,多条 INSERT 语句可以并发的执行,这也是三种锁模式中扩展性最好的一种。
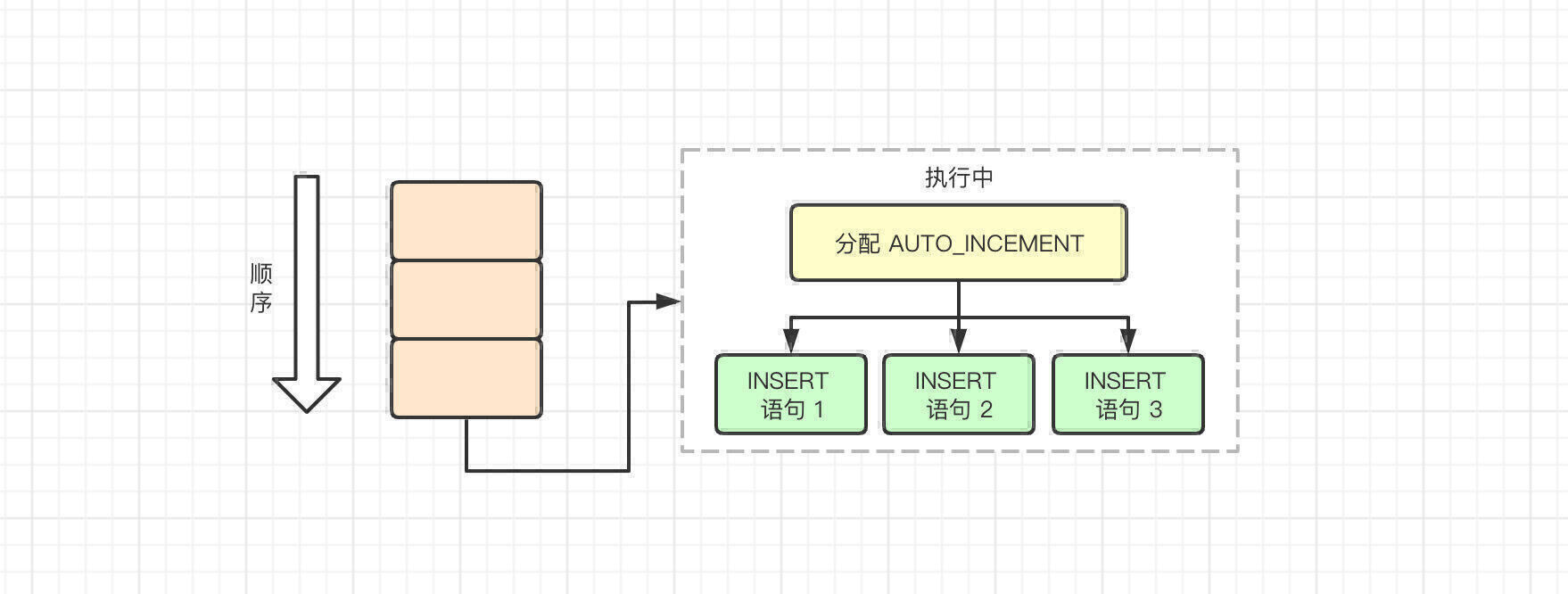
并发执行所带来的副作用就是单个 INSERT 的自增值并不连续,因为 AUTO_INCREMENT 的值分配会在多个 INSERT 语句中来回交叉的执行。
优点很明确,缺点是在并发的情况下无法保证数据一致性,这个下面会讨论。
交叉模式缺陷
要了解缺陷是什么,还得先了解一下 MySQL 的 Binlog。Binlog 一般用于 MySQL 的数据复制,通俗一点就是用于主从同步。在 MySQL 中 Binlog 的格式有 3 种,分别是:
- Statement 基于语句,只记录对数据做了修改的SQL语句,能够有效的减少binlog的数据量,提高读取、基于binlog重放的性能
- Row 只记录被修改的行,所以Row记录的binlog日志量一般来说会比Statement格式要多。基于Row的binlog日志非常完整、清晰,记录了所有数据的变动,但是缺点是可能会非常多,例如一条
update语句,有可能是所有的数据都有修改;再例如alter table之类的,修改了某个字段,同样的每条记录都有改动。 - Mixed Statement和Row的结合,怎么个结合法呢。例如像
alter table之类的对表结构的修改,采用Statement格式。其余的对数据的修改例如update和delete采用Row格式进行记录。
如果 MySQL 采用的格式为 Statement ,那么 MySQL 的主从同步实际上同步的就是一条一条的 SQL 语句。如果此时我们采用了交叉模式,那么并发情况下 INSERT 语句的执行顺序就无法得到保障。
可能你还没看出问题在哪儿,INSERT 同时交叉执行,并且 AUTO_INCREMENT 交叉分配将会直接导致主从之间同行的数据主键 ID 不同。而这对主从同步来说是灾难性的。
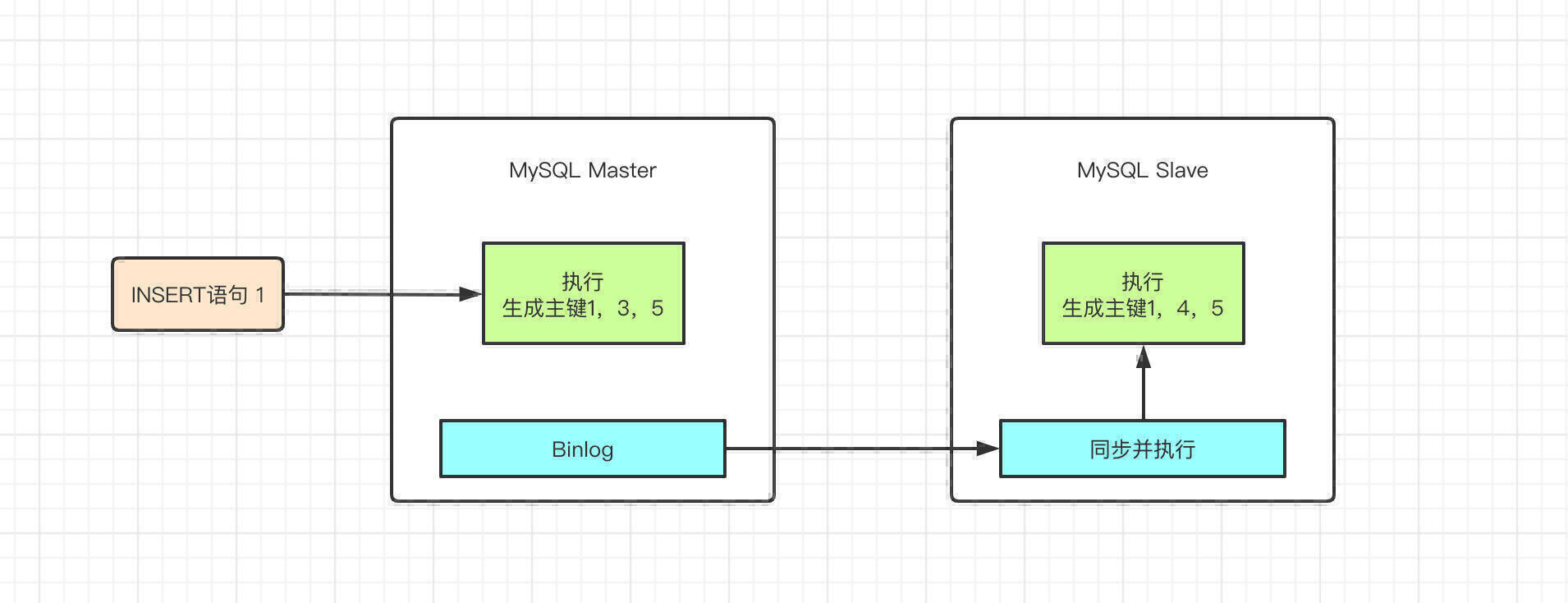
换句话说,如果你的 DB 有主从同步,并且 Binlog 存储格式为 Statement,那么不要将 InnoDB 自增锁模式设置为交叉模式,会有问题。其实主从同步的过程远比上图中的复杂,之前我也写过详细的MySQL主从同步的文章,感兴趣可以先去看看。
而后来,MySQL 将日志存储格式从 Statement 变成了 Row,这样一来,主从之间同步的就是真实的行数据了,而且 主键ID 在同步到从库之前已经确定了,就对同步语句的顺序并不敏感,就规避了上面 Statement 的问题。
基于 MySQL 默认 Binlog 格式从 Statement 到 Row 的变更,InnoDB 也将其自增锁的默认实现从连续模式,更换到了效率更高的交叉模式。
鱼和熊掌
但是如果你的 MySQL 版本仍然默认使用连续模式,但同时又想要提高性能,该怎么办呢?这个其实得做一些取舍。
如果你可以断定你的系统后续不会使用 Binlog,那么你可以选择将自增锁的锁模式从连续模式改为交叉模式,这样可以提高 MySQL 的并发。并且,没有了主从同步,INSERT 语句在从库乱序执行导致的 AUTO_INCREMENT 值不匹配的问题也就自然不会遇到了。
总结
你可能会说,为啥要了解这么深?有啥用?
其实还真有,例如在业务中你有一个需要执行 几十秒 的脚本,脚本中不停的调用多次 INSERT,这时就问你这个问题,在这几十秒里,会阻塞其他的用户使用对应的功能吗?
如果你对自增锁有足够的了解,那么这个问题将会迎刃而解。