搜索引擎告诉你如何大海捞针
搜索引擎告诉你如何大海捞针
如果问你这个问题:
像搜索引擎这样的全文搜索底层原理到底是什么?
对于有经验的人来说,很轻松的就能回答这个问题。因为现代的搜索引擎基本都是采用倒排索引来实现的。那什么是倒排索引呢?
建立倒排索引
有的同学看到「倒排」两个字可能有点慌。
我知道你很急,但你先别急(bushi)
这个不是「倒排需求」的倒排,而是「倒排索引」的倒排。假设我们现在有 3 个网页,包含了如下很简单的内容:
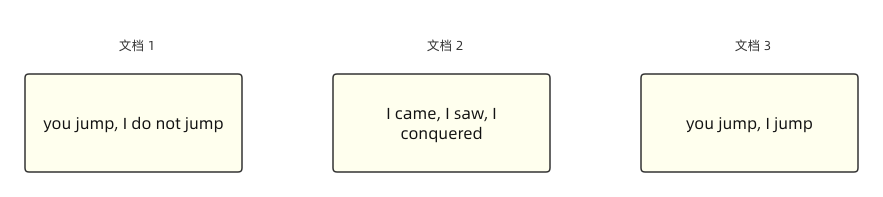
现在假设我们要对网页中的内容进行搜索,第一步需要做什么呢?当然是建立索引,没有索引你还想大海捞针?想 peach,相信大家对索引应该不陌生,大家平时看书时看到的目录,是一种索引,MySQL 当中的聚簇索引和非聚簇索引也是一种索引。
废话不多说,直接看人肉手动分词 + 建立道倒排索引之后的结果:
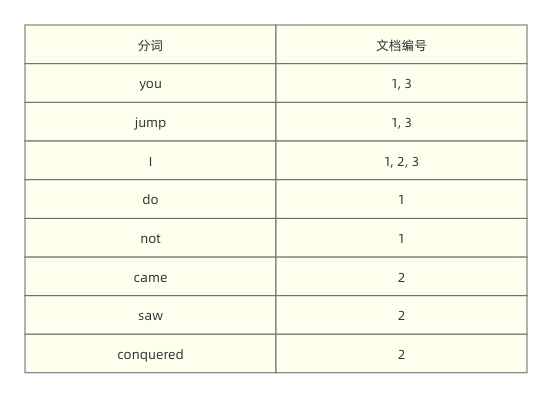
假设现在要搜索 jump 这个词,那么最终就会把网页 1、2 展示给你,因为 jump 在两个网页中都出现过。这就是很简单的一个倒排索引的例子。
搜索连续的词怎么办?
可能大家还没有意识到这个问题在哪里,我们举个例子来看看。在搜索引擎里搜索的时候,我们输入 i jump 和 "i jump" 是不同的概念。前者代表包含了 i 和 jump 两个词的网页,后者代表了单词 i 后紧跟 jump 的网页。例如,搜索 i jump 预期会把上面 3 个网页全部搜索出来,而搜索 "i jump" 则只会搜索出网页 3.
此时我们思考一个问题,搜索引擎是如何实现上面功能的呢?在上面的索引表中,只有哪些词出现在了哪些网页当中,却并没有词语位置的相关信息。
所以,只记录词语出现在哪些网页中是远远不够的。为了满足上面精确到词语位置的查询需求,让我们把词语的位置也一起写入到索引中,如下所示:
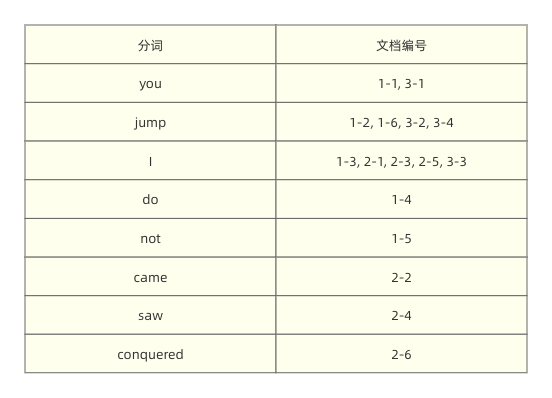
这样以来,当我们搜索 "i jump" 时,我们就能够通过索引中记录的位置来搜索相邻的词语,如下图所示:
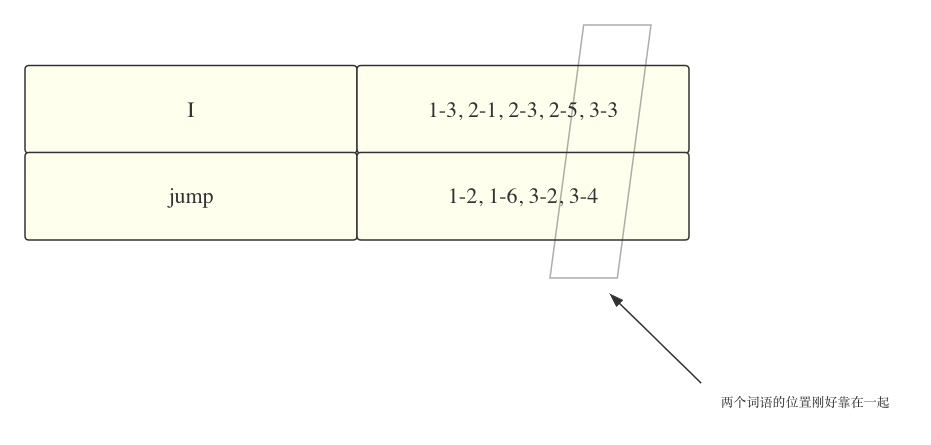
词语 I 在 3-3 的位置,而 jump 在 3-4,由此就可以推断,这两个词在同一个网页的相邻的位置了。
只搜索标题的内容怎么办?
现在 Google 是支持这种搜索的,查询的格式如下:intitle:${search_content},大家可以去尝试一下。
那这个到底是怎么实现的呢?
很显然上面的索引是无法满足只搜标题这个需求的,因为它无法判断当前这个词是标题还是正文,那这个到底是怎么实现的?
首先,我们得知道如何标识「标题」。如果我们在现在的网友上右键,选择查看源代码,你就会看到 HTML,这才是网页的“真面目。网页的标题会用 <title></title> 标签给包裹起来,而正文会用 <body></body> 标签给包裹起来,那比如我们现在给上面的 3 个网页加上 title 标签,那么网页就会变成这样:
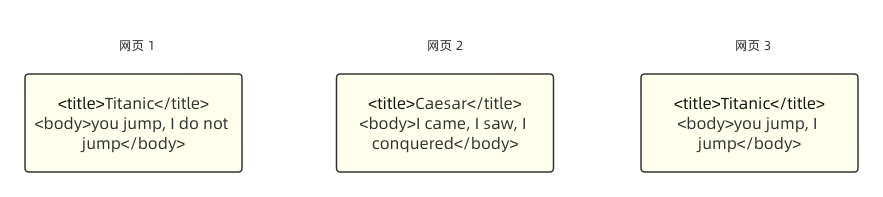
既然网页的内容发生了“变更”(实际上没有,因为它本来就应该长这样,只不过为了满足循序渐进的讲解才这么说),那么索引也自然需要更新一下。因为本质上我们需要知道哪些词是标题,那么新增了这部分信息的索引就如下所示:
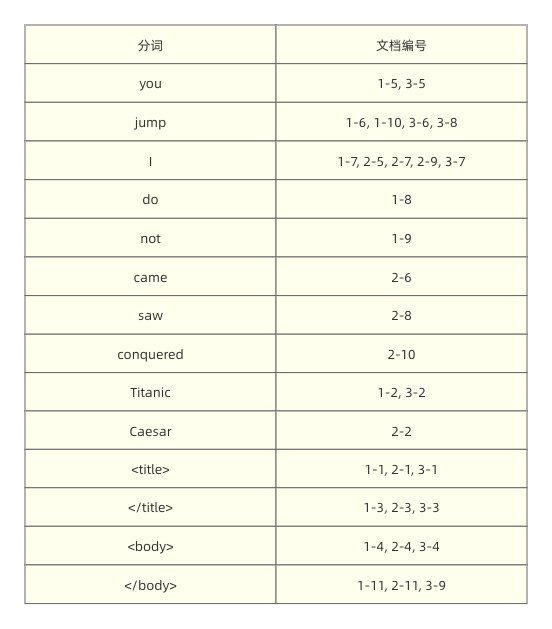
可以看到,标题的文本、以及标识标题的标签都被写入了索引,通过这些信息我们就能够判断当前的词是否是标题。比如举个例子,我们搜索 intitle:Caesar,这个时候首先会通过索引找到词语 Caesar,发现它只出现在网页 2 的位置 2,那么我们再对比 <title> 和 </title> 出现的位置我们会发现,2-2 刚好在标题的范围内:
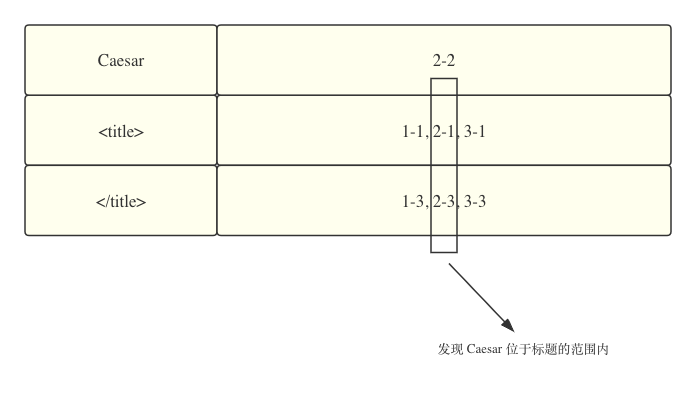
这样一来,我们就能够将搜索的范围限制在标题内了。