缓存与数据库的双写一致性
缓存与数据库的双写一致性
这几天瞎逛,不知道在哪里瞟到了缓存的双写,就突然想起来这块虽然简单,但是细节上还是有足够多我们可以去关注的点。这篇文章就来详细聊聊双写一致性。
首先我们知道,现在将高速缓存应用于业务当中已经十分常见了,甚至可能跟数据库的频率不相上下。你的用户量如果上去了,直接将一个裸的 MySQL 去扛住所有压力明显是不合理的。
这里的高速缓存,目前业界主流的就是 Redis 了,关于 Redis 相关的文章,之前也有聊过,在此就不赘述,感兴趣的可以看看:
额,不列出来我都没感觉关于 Redis 我居然写了这么多...言归正传。
在我们的业务中,普遍都会需要将一部分常用的热点数据(或者说不经常变但是又比较多的数据)放入 Redis 中缓存起来。下次业务来请求查询时,就可以直接将 Redis 中的数据返回,以此来减少业务系统和数据库的交互。
这样有两个好处,一个是能够降低数据库的压力,另一个自不必说,对相同数据来说能够有效的降低 API 的 RT(Response Time)。
后者其实还好,降低数据库的压力显得尤为重要,因为我们的业务服务虽然能够以较低的成本做到横向扩展,但数据库不能。
这里的不能,其实不是指数据库不能扩展。MySQL 在主从架构下,通过扩展 Slave 节点的数量可以有效的横向扩展读请求。而 Master 节点由于不是无状态的,所以扩展起来很麻烦。
对,是很麻烦,也不是不能横向扩展。但是在那种架构下,我举个例子,主-主架构下,会带来很多意向不到的数据同步问题,并且对整个的架构引入了新的复杂性。
就像我在之前写的MySQL 主从原理中提到过的一样,双主架构更多的意义在于 HA,而不是做负载均衡。
所以,相同的数据会同时存在 Redis 和 MySQL 中,如果该数据并不会改变,那就完美的一匹。可现实很骨感,这个数据99.9999%的概率是一定会变的。
为了维护 Redis 和 MySQL 中数据的一致性,双写的问题的就诞生了。
Cache Aside Pattern
其中最经典的方案就是 Cache Aside Pattern ,这套定义了一套缓存和数据库的读写方案,以此来保证缓存和数据库中的数据一致性。
具体方案
Cache Aside Pattern 具体又分为两种 Case,分别是读和写。
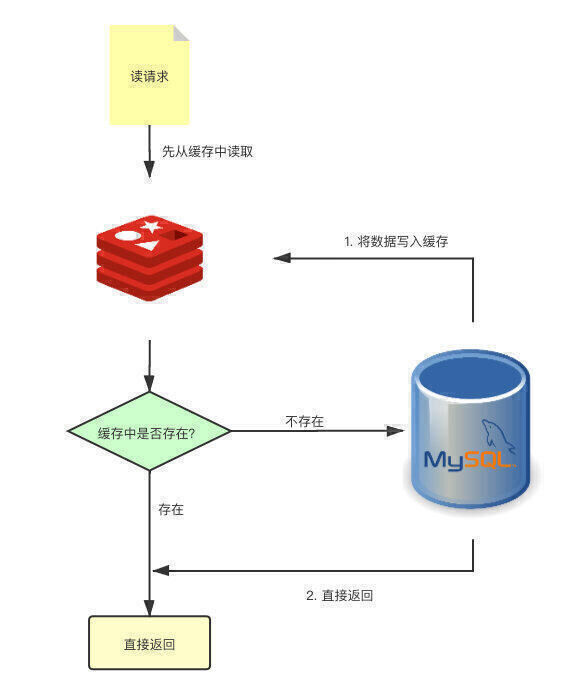
对于读请求,会先去 Redis 中查询数据,如果命中了就会直接返回数据。而如果没有从缓存中获取到,就会去 DB 中查询,将查询到的数据写回 Redis,然后返回响应。
而更新则相对简单,但是也是最具有争议。当收到写请求时,会先更新 DB 中的数据,成功之后再将缓存中的数据删除。
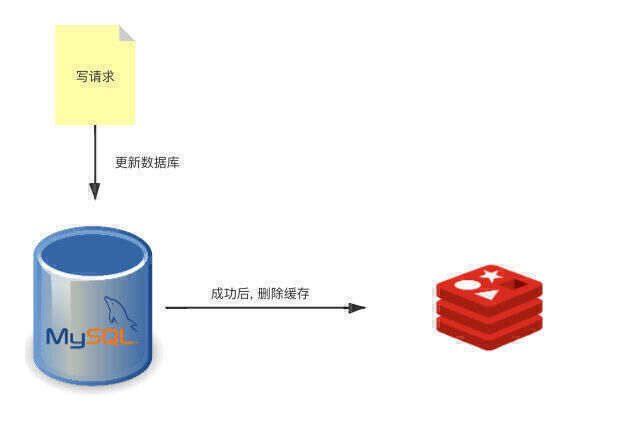
注意这里是删除,而不是更新。因为实际生产中,缓存中存放的可能不仅仅是单一的像 true、false或者1、19这种值。
为什么是删除
还有可能在缓存中存放一整个结构体,其中包含了非常多的字段。那么是不是每次有一个字段更新就都需要去把数据从缓存中读取出来,解析成对应的结构体,然后更新对应字段的值,再写回缓存呢?又或者你是直接将原缓存删除,然后又将最新的数据写入缓存?
其实乍一看,好像没有毛病。我更新难道不应该这么更新吗?在这里,我们的关注点更多的放在了更新的方式上,而把更多的必要性给忽略到了。我们更新了这个值之后,在接下来的一段时间内,它会被频繁访问到吗?可能会,但也可能根本不会被访问到了。
那既然有可能不会被访问到, 那我们为啥还要去更新它?而且,更新缓存所带来的开销有时侯会非常大。
然而这还只是缓存数据源单一的情况,如果缓存中缓存的是某个读模型,其数据是通过多张表的数据计算得出的,其开销会更大。
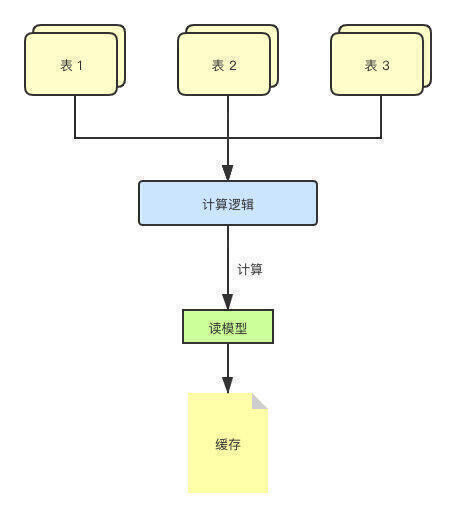
读模型,简单理解就是用现有数据,计算、统计出来的一些数据。
这个思路就类似于懒加载的方式,只在需要的时候去计算它。
争议在哪儿?
前面提到过,更新时顺序为先更新 DB 中的数据,成功之后再删除缓存。但是也有人认为应该先删除缓存,再去更新 DB 中的数据。
乍一看,可能并不能发现问题。甚至觉得还有那么一丝丝合理。因为如果先删除缓存,如果删除操作失败,DB 中的数据也不会更新,这样缓存和 DB 中数据也能保证一致性。而且,如果删除缓存成功,但更新 DB 失败了,大不了下次获取时,再将数据写回缓存即可,可以说十分的合理。
但,这只是单线程的情况下,如果在多线程下,会直接造成致命的数据不一致。
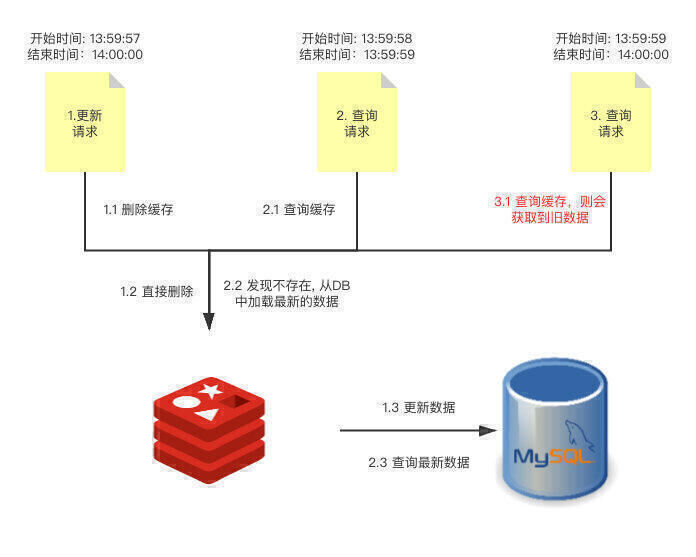
上面的流程图详细的描述了情况,更新请求1刚刚把缓存中的数据删除,查询请求2就过来了,查询请求2会发现缓存中是空的,所以按照 Cache Aside Pattern 的读请求标准,会从 DB 中加载最新的数据并将其写入缓存。而此时更新请求1还没有对 DB 进行更新操作,所以查询请求2写入到缓存中的数据仍然是旧数据。
这样一来,查询请求3在下一次更新之前,读取到的就都会是老数据。然后,更新请求1将最新的数据更新至 DB,缓存和 DB 的数据就不一致了。
其实 Cache Aside Pattern 中的模式,仍然会在某些 case 下造成数据不一致。但是这个概率非常的低,因为触发这个不一致的情况的条件太苛刻了。
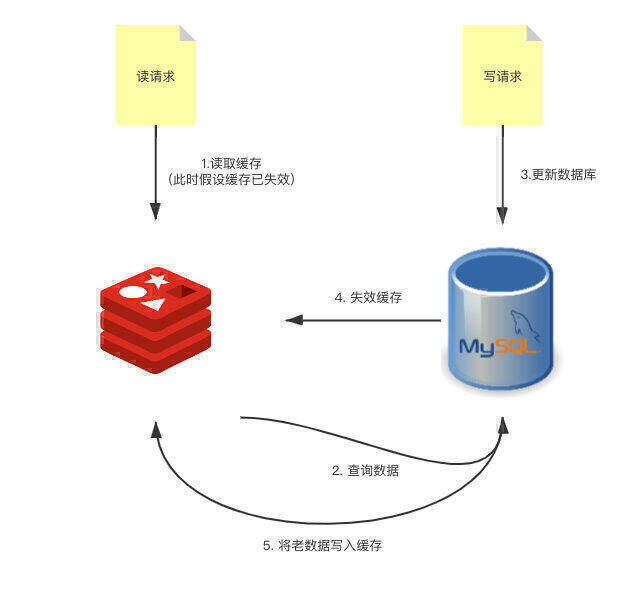
首先是缓存要失效,然后读请求、写请求并发的执行,并且读请求要比写请求后执行完。为啥说概率不大呢,首先在实际生产中,读请求一般都要比写请求快得多。除此之外,读请求去 DB 请求数据的时间一定要早于写请求,并且写缓存的时间还要一定晚于写请求,比起最开始的那种情况来说,条件已经是非常的严格了。
如果完全不能容忍,可以通过 2PC 的模式去保证数据的一致性,也可以通过将请求串行化的方式来解决,但这样的代价就是会牺牲并发量。
End
其实还有其他的几种方案,比如 Read Throught Pattern 、Write Through Pattern、Write Around、Write Behind Caching Pattern 等等。但是这些相对于 Cache Aside Pattern 来说比较简单,可以自己去了解一下就好。